(一)数据预处理
在对国际数字生态指数进行测算之前,我们通过以下三种方式对数据进行了预处理。
1. 缺失值插补
针对部分国家缺失最新数据的情况,首先采用冷卡插补法,收集该国在缺失指标上的既往数据进行填充;如果该国既往数据仍然缺失,则使用平均值插补法。
2. 部分数据对数化处理
由于一些反映对象规模总量的数据(如网民数量)的绝对数值大、各国之间的差异大,导致这部分数据呈现偏态分布。本研究对以上数据进行对数化处理,以令其更接近正态分布的情况,便于后续的指数计算。
3. 标准化
在计算指标权重和指标聚合之前,采取“最小-最大”(Min-Max)标准化方法,将除数据规制注3部分外的底层数据统一转化到[10,100]区间,作为对四级指标的测度,公式如下所示:
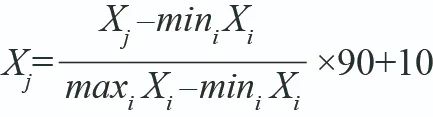
(二)指标权重计算方法
我们主要使用加权聚合的方式对国际数字生态的总指数得分进行测算。在一级指标以下的加权聚合中,主要使用自编码器法(Autoencoder)和熵值法进行指标权重计算。最终的总指数得分通过对数字基础、数字能力、数字应用和数字规制这四个一级指标得分等权加总得到。
1. 自编码器法
自编码器法是一种能对数据实现降维的无监督的机器学习算法,其基本原理为:将输入的高维度数据利用一个神经网络编码器得到一组新的低维度数据,再利用一个神经网络解码器输出一组高维度数据,力图重构原始输入(参见图2)。通过最小化输入数据与输出数据之间的重构误差来训练模型,进而能得到图中神经网络各连边上的权重,中间得到的编码可以看作是输入数据的主要特征。研究对数字基础、数字能力和数字应用三个一级指标使用自编码器法计算权重和得分。
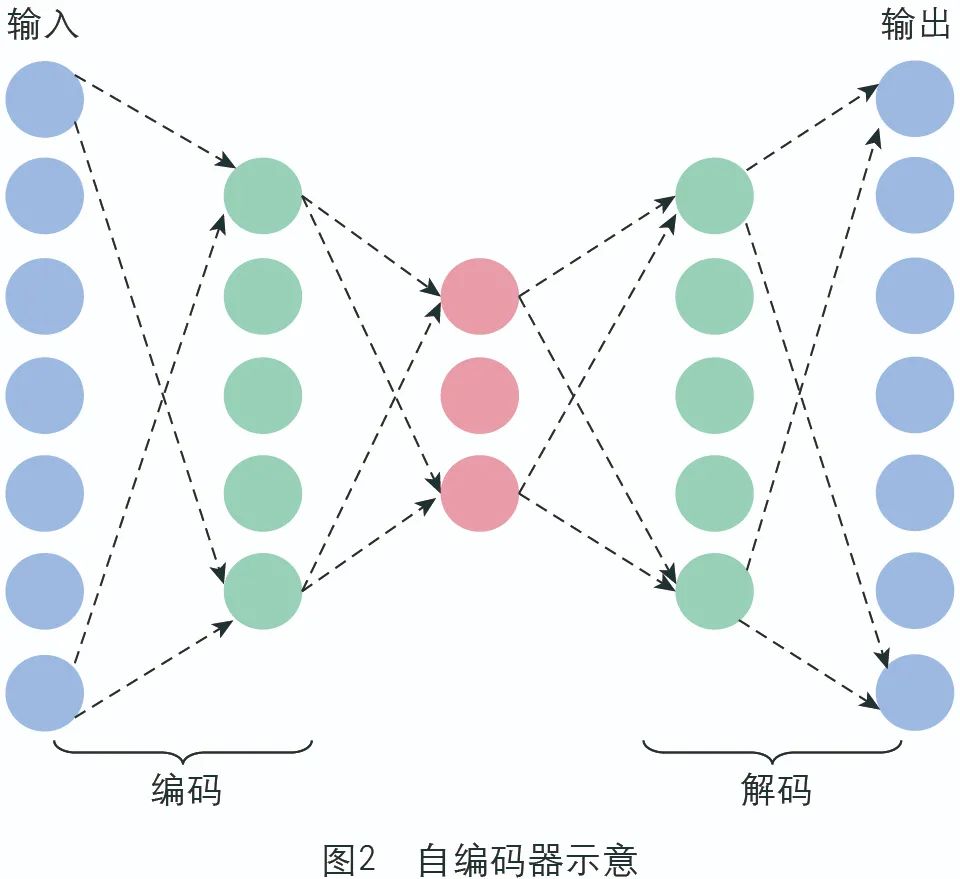
该算法模型可以运用到对指标权重的计算中来。根据国际数字生态指数指标体系设置(参见表1),我们可以将具体测量指标作为自编码器中的输入数据,将三级指标、二级指标和一级指标作为神经网络的隐藏层,根据指标间层级关系结构建立神经网络中的连边。这样,由模型训练得到神经网络中连边上的权重即可作为指标聚合时使用的权重,由自编码器得到的数据降维结果(即图1中的“编码”部分),即可作为对应一级指标的得分。自编码器作为机器学习领域的经典算法,过去多用于自然语言处理和图像处理,这里创造性地将其运用在对指标权重的计算之中,据我们文献调研,这在指数构建的研究中属首例。
2. 熵值法
与自编码器法不同,熵值法是一种自动计算指标权重的常用方法,它依靠数据分布的离散程度来确定指标权重的大小。在信息论中,熵是对概率分布不确定性的一种度量,对于随机变量X,其概率分布为p(x),定义熵如下:
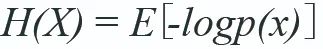
具体而言,在计算指标聚合的权重时,需将经归一化处理的测量指标转换为一个离散概率分布:
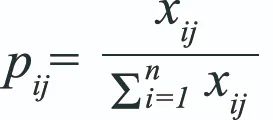
其中,xij为个案i(本研究中为国家)在指标j上的水平,它是指标原始取值经标准化处理后的结果。pij是对它们进行归一化得到的结果,进而我们能将其看作[0,1]区间上的一个离散分布。如果该指标的分布比较集中,即意味着其区分性不强,该概率分布的信息量较大,不确定性较小,熵比较小;反之,如果该指标的分布较为分散,则其区分性较大,不确定性很大,熵比较大。根据熵的这一特性,我们计算指标分布的熵值来判断此指标的离散程度ej:
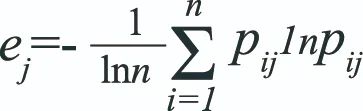
更进一步,再将各个指标的熵值转化为权重,指标的区分度越高的,则该指标的权重更大:
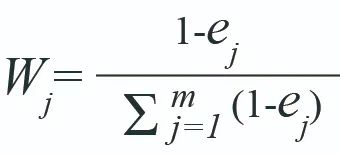
在本研究中,我们使用熵值法确定了数字规制部分的各层级指标权重。
3. 以等权方式生成国际数字生态总指数
在使用自编码器法和熵值法完成对数字基础、数字能力、数字应用和数字规制这四个维度下的指标权重计算,形成四个一级指标得分之后,以等权的方式,即每个一级指标的权重均为0.25,生成国际数字生态的总指数,以此来综合判断各国数字生态的发展现状。
邮箱: gdsjsys@pku.edu.cn
地址:北京市海淀区颐和园路5号
邮编:100871
官方微信
 渝公网安备50009802002192
渝公网安备50009802002192